

As Redes Neurais Recorrentes (RNNs) revolucionaram o Processamento de Linguagem Natural (PLN), permitindo a criação de modelos capazes de capturar padrões complexos em textos. Neste tutorial, vamos construir um modelo de linguagem baseado em RNN utilizando Python e TensorFlow/Keras, treinado para prever palavras a partir de um corpus textual.
Vamos do pré-processamento dos dados até o treinamento da rede neural e a geração de texto!
1. Instalando as Dependências
Para começar, instale as bibliotecas necessárias:
pip install tensorflow nltk numpy
Agora, importamos os pacotes essenciais:
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as np
import nltk
nltk.download('punkt')
2. Preparando o Corpus
Vamos utilizar um conjunto de textos para treinar o modelo.
corpus = """O Senhor Ministro Dias Toffoli relatou o caso.
A decisão foi unânime. O julgamento ocorreu no STF."""
# Tokenizando o texto
tokens = nltk.word_tokenize(corpus.lower())
print(tokens)
Isso transforma o texto em uma lista de palavras minúsculas:
['o', 'senhor', 'ministro', 'dias', 'toffoli', 'relatou', 'o', 'caso', '...', 'stf']
3. Criando o Vocabulário e Sequências Numéricas
Transformamos as palavras em números para que a RNN possa processá-las:
tokenizer = Tokenizer()
tokenizer.fit_on_texts([corpus])
# Convertendo o texto em sequências numéricas
sequences = tokenizer.texts_to_sequences([corpus])[0]
print(sequences)
Saída esperada:
[1, 2, 3, 4, 5, 6, 1, 7, ..., 10]
Criamos pares de entrada-saída para o treinamento:
X = []
y = []
for i in range(1, len(sequences)):
X.append(sequences[:i])
y.append(sequences[i])
# Padronizando os tamanhos
X = pad_sequences(X, padding='pre')
y = np.array(y)
4. Criando e Treinando a Rede Neural Recorrente
Agora, construímos um modelo RNN com camada de embedding e uma camada SimpleRNN:
vocab_size = len(tokenizer.word_index) + 1 # Tamanho do vocabulário
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, 100, input_length=X.shape[1]),
tf.keras.layers.SimpleRNN(150, return_sequences=False),
tf.keras.layers.Dense(150, activation='relu'),
tf.keras.layers.Dense(vocab_size, activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X, y, epochs=20, verbose=1)
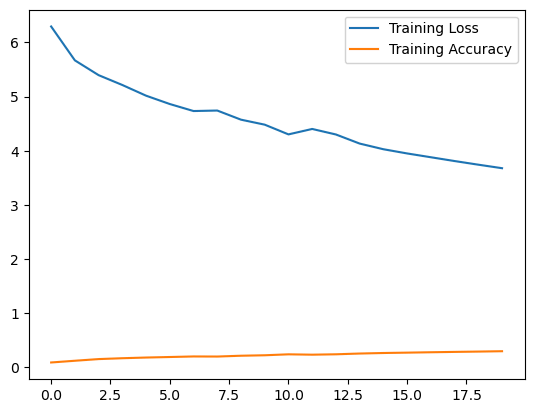
O modelo será treinado por 20 épocas para aprender padrões no texto. A figura a seguir mostra o decaimento do erros e o ganho de acurácia durante o treinamento do modelo nos experimentos que realizamos.
5. Gerando Texto com a RNN
Agora podemos gerar frases com base na rede neural treinada. Configuramos para que, por padrão, as frases geradas tenham um tamanho de 5 palavras, a partir das palavras iniciais. No exemplo é passado a “O julgamento” e frase é continuada pelo modelo RNN com base nos dados de treinamento.
def gerar_texto(model, tokenizer, seed_text, num_palavras=5):
for _ in range(num_palavras):
sequence = tokenizer.texts_to_sequences([seed_text])[0]
sequence = pad_sequences([sequence], maxlen=X.shape[1], padding='pre')
predicted_index = np.argmax(model.predict(sequence, verbose=0))
predicted_word = tokenizer.index_word.get(predicted_index, '')
seed_text += ' ' + predicted_word
return seed_text
print(gerar_texto(model, tokenizer, "O julgamento", num_palavras=5))
Exemplo de saída gerada:
"O julgamento foi realizado no plenário do STF"
6. Avaliando a Qualidade do Modelo com Perplexidade
A perplexidade mede a incerteza do modelo sobre a próxima palavra:
import math
def calcular_perplexidade(model, tokenizer, sequences):
total_log_prob = 0
num_words = 0
for seq in sequences:
for i in range(1, len(seq)):
input_seq = pad_sequences([seq[:i]], maxlen=X.shape[1], padding='pre')
true_word = seq[i]
predictions = model.predict(input_seq, verbose=0)
predicted_prob = predictions[0][true_word]
total_log_prob += math.log(predicted_prob + 1e-10)
num_words += 1
return math.exp(-total_log_prob / num_words)
perplexidade = calcular_perplexidade(model, tokenizer, [sequences])
print(f"Perplexidade: {perplexidade}")
Quanto menor a perplexidade, melhor o modelo!
Conclusão
Criamos um modelo de linguagem baseado em RNN que gera texto coerente a partir de um corpus. Com ajustes e mais dados, podemos melhorar sua precisão e capacidade de generalização.
Caso queira o código completo, com detalhes dos experimentos, solicite-nos via comentário.
Veja também nosso post mostrando a criação de um modelo de linguagem baseado em N-gramas.
Fique ligado no Janela do Dev para mais tutoriais sobre Inteligência Artificial e PLN!
Gostou do tutorial? Comente abaixo e compartilhe sua opinião!


