Criando um Corretor Ortográfico com Python e o Algoritmo de Smith-Waterman
Aprenda a criar um corretor ortográfico simples em Python usando o algoritmo de Smith-Waterman para encontrar e corrigir palavras erradas!
Leia maisUma janela aberta para o mundo da Informática, Programação e da Inteligência Artificial.


Aprenda a criar um corretor ortográfico simples em Python usando o algoritmo de Smith-Waterman para encontrar e corrigir palavras erradas!
Leia mais
Construindo um modelo de linguagem utilizando Redes Neurais Recorrentes. As RNNs permitem a criação de modelos capazes de capturar padrões complexos em textos.
Leia mais
Criar um modelo de linguagem com N-gramas é um ótimo ponto de partida para entender como as máquinas processam texto. Apesar de ser um método simples, ele é bastante útil para corretores ortográficos, sistemas de autocompletar e chatbots básicos.
Leia mais
A tokenização é um passo essencial no processamento de dados textuais. Ao dividir o texto em unidades significativas, ela potencializa os algoritmos.
Leia mais
As expressões regulares são uma ferramenta poderosa e versátil no processamento de texto, com a capacidade de definir padrões complexos de maneira eficiente.
Leia mais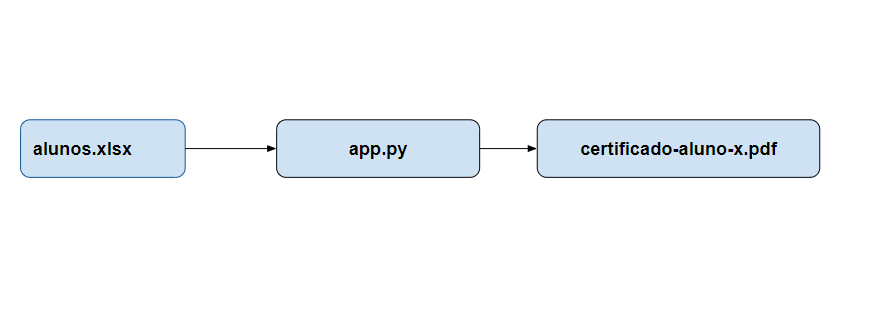
Neste tutorial utilizaremos o python para automatização na geração de certificados. Para as bibliotecas openpyxl para leitura de informações de alunos/participantes no formato de planilha do Microsoft Excel (.xlsx) e docx a geração dos certificados em formato docx. Com a função para a geração dos certificados vamos agora iterar sobre a lista de alunos para […]
Leia mais
Quando se trata de tarefas de Processamento de Linguagem Natural (NLP), a qualidade dos dados é de suma importância, ela tem impacto direto nos resultados obtidos. Os modelos que utilizam a arquitetura Transformer, como os modelos baseados no Bidirectional Encoder Representations from Transformers – BERT provaram alcançar resultados impressionantes na compreensão de texto, mas eles […]
Leia mais
No campo do Processamento de Linguagem Natural (PLN), a capacidade de compreender e manipular a linguagem é fundamental. Uma das tarefas mais importantes é a vetorização de sentenças, que consiste em converter texto em uma representação numérica que pode ser entendida e processada por algoritmos de aprendizado de máquina. Nesse sentido, a biblioteca SentenceTransformers, baseada […]
Leia mais
Neste post, iremos explorar a implementação de um classificador binário utilizando o algoritmo de K-Vizinhos Mais Próximos (KNN) a partir do pacote Scikit-Learn. Iremos passar por todos os passos necessários, desde a conceitualização até a avaliação do classificador, usando um conjunto de dados simulado de comentários sobre o atendimento ao cliente de uma loja virtual […]
Leia mais